GEDmatch Numbers
Back to BlogsAfter uploading to GEDmatch and viewing your One-to-Many or One-to-One reports, one of the first questions you will have is “What the !@#$ are all these numbers?” Don’t freak out. They are fairly simple to understand.
First, before we discuss the results, you will want to have a relationship predictor handy. You can use mine or you can view the charts on ISOGG. Now, that you’re prepared, let’s look at a section of the results of my One-to-Many.
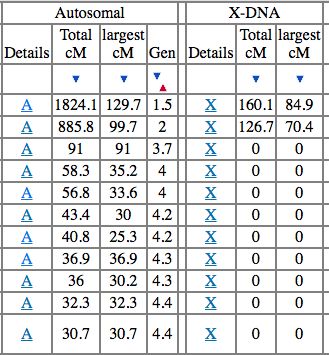
Towards the middle of the columns, you will see a section for Autosomal and X-DNA. For now, completely ignore your X-DNA—especially if you’re a newbie.
The key columns you want to first investigate are the Total cM and Gen.
The Total cM column shows how much autosomal DNA you share with your relative. The higher the number is, the closer your match. In my example above, the first match and I share 1824.1 cM. That’s a great match. After reviewing your charts, you’ll see there are many possibilities for this amount of shared DNA including: Grandparent/grandchild, aunt-or-uncle/niece-or-nephew, or half-siblings.
The Gen column for the match with 1824.1 cM shows 1.5. This is an estimate made by GEDmatch of how many degrees to our shared ancestor. Again, this number is an estimate.
Since I’m a male, the X-DNA could actually be important for this very close match (and it was). We share a large chunk of X-DNA. The only way a male gets X-DNA is from their mother.
For me, the results suggested three possibilities of how we are related:
- my biological mother and this female share a mother (making her an aunt);
- my biological mother could be her biological mother (half-sister);
- my biological mother’s mother (grandmother).
All of these scenarios fit with the data from ISOGG.
But wait, there’s another person under her. This person shared the same email address (suggesting one of them was the admin for both kits). The DNA is almost half of the first match (885.8 cM) and she shares a large chunk of X-DNA with me and the top match. This suggested to me that the second match was a daughter of the first match. This is all speculation without following up.
There’s an unscientific theory that adoptions run in families among many Search Angels and detectives. This led me to believe she was a half-sister that had been placed for adoption and the second match was her child. The second option was that she was my aunt and possibly placed a child for adoption and was seeking them though DNA. Both scenarios could lead to someone testing their DNA.
I decided to do a 23andMe test and give rights to administer to a close friend. Doing so could allow me to discover more info rather than reaching out by email and possibly shaking things up without knowing the relationship. Also, I wasn’t necessarily looking for a reunion.
Turns out, this match was indeed my biological aunt. So, the charts were right and the DNA did indicate the right relationship.
Notes
There are many other things you can take away from the One-to-Many results. Here area few:
- In the first column, you can determine where the test was taken by the letter at the beginning of the kit: A = Ancestry; M=23andMe; T = FTDNA.
- The final columns contain contact info. You can potentially harvest real names, real names from email addresses (ex. john.smith@gmail.com), usernames (jsmith123@gmail.com where jsmith123 could be a searchable username in Google).
- X-DNA is generally not looked at by many. Normally it’s not helpful. In my situation above, it was extremely helpful in determining maternal line.